
redis的多机数据库实现,主要分为以下三种:
- Redis哨兵(Sentinel)
- Redis复制(主从)
- Redis集群
为提高存储容量和响应速度,一般公司都会搭建Redis集群来保证服务高可用。本文主要记录下如何基于Docker快速搭建Redis集群并在SpringBoot中整合使用。
还有各种喜闻乐见的坑:如使用lua脚本报错、redis-cli版本问题等。
涉及到的技术和相关版本如下:
Docker 19.03 Docker Compose 1.25 Redis 5.0.5 SpringBoot 2.2 CentOS 7
Redis集群不同一致性哈希,它用一种不同的分片形式,在这种形式中,每个key都是一个概念性(hash slot)的一部分。Redis集群中的每个节点负责一部分hash slots,并允许添加和删除集群节点。
哈希槽(hash slot)
来自Redis Cluster的概念, 但在各种集群方案都有使用。 哈希槽是一个key的集合,Redis集群共有16384个哈希槽,每个key通过CRC16散列然后对16384进行取模来决定该key应当被放到哪个槽中,集群中的每个节点负责一部分哈希槽。
以有三个节点的集群为例:
┠ 节点A包含0到5500号哈希槽
┠ 节点B包含5501到11000号哈希槽
┠ 节点C包含11001到16384号哈希槽
这样的设计有利于对集群进行横向伸缩,若要添加或移除节点只需要将该节点上的槽转移到其它节点即可。在某些集群方案中,涉及多个key的操作会被限制在一个slot中,如Redis Cluster中的mget/mset操作。此时需要HashTag来帮助实现相关操作,详见下文。
为了保持可用,Redis集群采用master-slave模式,每个hash slot就有1到N个副本。而redis-cluster规定,至少需要3个master和3个slave。即3个master-slave对。
当我们给每个master节点添加一个slave节点以后,我们的集群最终会变成由A、B、C三个master节点和A1、B1、C1三个slave节点组成,这个时候如果B失败了,系统仍然可用。节点B1是B的副本,如果B失败了,集群会将B1提升为新的master,从而继续提供服务。然而,如果B和B1同时失败了,那么整个集群将不可用。
Redis集群不能保证强一致性。换句话说,Redis集群可能会丢失一些写操作,原因是因为它用异步复制。
1、准备工作
1.1 安装Docker Compose
Docker Compose
是一个用于定义和运行多个docker容器应用的工具。使用Compose可以用YAML文件来配置你的应用服务,然后只需要使用一个命令,就可以部署配置好的所有服务。github: https://github.com/docker/compose
curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.1/docker-compose-`uname -s`-`uname \
-m` -o /usr/local/bin/docker-compose修改执行权限:
chmod +x /usr/local/bin/docker-compose
查看是否安装成功:
docker-compose --version

1.2 准备配置文件
这里使用1个普通redis实例+5个dockerRedis实例的方式来搭建,机器里就有一个单例redis直接拿来用了,其实…正常来说要么分两台机器,一台3个Master一台3个slave来组建,或者直接一台机器起6个docker。但由于我就俩机器,另一个还被十多个服务挤爆空间不够。。所以就凑合用一台 = =。在生产环境下应该是一台一个实例的。
1.3 创建目录和相关配置文件:
在服务器/home/路径下创建 redis-cluster 文件夹。并在里面创建下述 5个redis的conf文件、1个docker-compose.yml和1个redis.sh文件。
先为五个docker实例准备redis.conf文件,这五个docker实例启动端口分别为 6380,6381,6382,7001,7002 ,还有个本机的6379
rdis.conf文件有两种常见方式:
1、使用Includ方式,只配置关键的配置点
include /your_redis_conf_file_path
port 6380
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
# redis默认使用rdb来持久化,这里不做任何改动,若需要aof请自行配置。2、使用完整.conf文件也是配置如上几个点,二者其实没区别。
有个坑:
关于daemonize no/yes是否后台运行这个配置,如果你使用docker来运行。请把它注释掉或者改为no。否则会与docke compose后台启动命令冲突导致无法启动。
然后准备 docke compose 用到的配置文件 docker-compose.yml
version: "3"
services:
redis-master2:
image: redis:5.0 # 基础镜像
container_name: redis-master2 # 容器名称
working_dir: /config # 切换工作目录
environment: # 环境变量
- PORT=6380 # 会使用config/nodes-${PORT}.conf这个配置文件
ports: # 映射端口,对外提供服务
- 6380:6380 # redis的服务端口
- 16391:16391 # redis集群监控端口
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
network_mode: host # 使用host模式
privileged: true # 拥有容器内命令执行的权限
volumes:
# 配置文件目录映射到宿主机
# 将容器中的/config配置目录映射到了宿主机的/home/redis-cluster目录
- /home/redis-cluster:/config
entrypoint: # 设置服务默认的启动程序
- /bin/bash
- redis.sh
redis-master3:
image: redis:5.0
working_dir: /config
container_name: redis-master3
environment:
- PORT=6381
ports:
- 6381:6381
- 16395:16395
stdin_open: true
network_mode: host
tty: true
privileged: true
volumes:
- /home/redis-cluster:/config
entrypoint:
- /bin/bash
- redis.sh
redis-slave1:
image: redis:5.0
working_dir: /config
container_name: redis-slave1
environment:
- PORT=6382
ports:
- 6382:6382
- 16395:16395
stdin_open: true
network_mode: host
tty: true
privileged: true
volumes:
- /home/redis-cluster:/config
entrypoint:
- /bin/bash
- redis.sh
redis-slave2:
image: redis:5.0
container_name: redis-slave2
working_dir: /config
environment:
- PORT=7001
ports:
- 7001:7001
- 16394:16394
stdin_open: true
network_mode: host
tty: true
privileged: true
volumes:
- /home/redis-cluster:/config
entrypoint:
- /bin/bash
- redis.sh
redis-slave3:
image: redis:5.0
working_dir: /config
container_name: redis-slave3
environment:
- PORT=7002
ports:
- 7002:7002
- 16395:16395
stdin_open: true
network_mode: host
tty: true
privileged: true
volumes:
- /home/redis-cluster:/config
entrypoint:
- /bin/bash
- redis.sh
最后是 redis.sh 的脚本
#!/bin/bash
echo "启动: nodes-${PORT}.conf"
redis-server ./node-${PORT}.conf最后这个目录下应该有这些文件:
1.4 一键启动docker
cd进 /home/redis-cluster 路径,键入如下命令:
docke-compose up -d

这里也有坑:
不要看到绿色的done就以为启动成功,若你使用 docker ps 命令后发现并没有你想要运行的镜像,GG了。
解决办法是请使用 docke-compose up 命令再次运行,不要添加-d,直接把log打出来,会看到输出的启动信息,这些信息里会有你要的错误提示。
若一切正常,使用ps命令可以看到:

加上本机已经启动的6379,已经构成了可以搭建集群的基本要素。
2、搭建集群和启动
关键命令为 :
redis-cli --cluster
Redis Cluster 在5.0之后取消了ruby脚本 redis-trib.rb的支持(手动命令行添加集群的方式不变),将trib集成到了redis-cli里,避免了再安装ruby的相关环境,经历过的人都知道ruby是多么折腾。关于ruby可以参考这里。
直接使用redis-clit的参数–cluster 来取代。关于Cluster的相关说明可以查看官网。
附 help 命令:
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
–cluster create创建集群
创建方式有两种。
一种是直接使用 create + 全部ip+port的方式让其自动分配主从节点。
还有一种是自己指定主节点机器,手动添加从节点。
这里采用第二种。
先看第一种的命令:
/redis-cli --cluster create 192.168.163.132:6379 192.168.163.132:6380 192.168.163.132:6381 192.168.163.132:6382 192.168.163.132:6383 192.168.163.132:6384 --cluster-replicas 1下面是第二种手动指定三个主节点 6379,6380,6381:
/usr/local/redis/bin/redis-cli --cluster create 192.168.31.105:6379 192.168.31.105:6380 192.168.31.105:6381


然后分别添加从节点6382,7001,7002到主节点6379, 6380,6381
/usr/local/redis/bin/redis-cli --cluster add-node 192.168.31.105:6382 192.168.31.105:6379 --cluster-slave
# 从6382 到 主6379
# 同样命令执行 7001 到 6380 和 7002 到 6381查看状态:
/usr/local/redis/bin/redis-cli --cluster check 192.168.31.105:6380 --cluster-search-multiple-owners
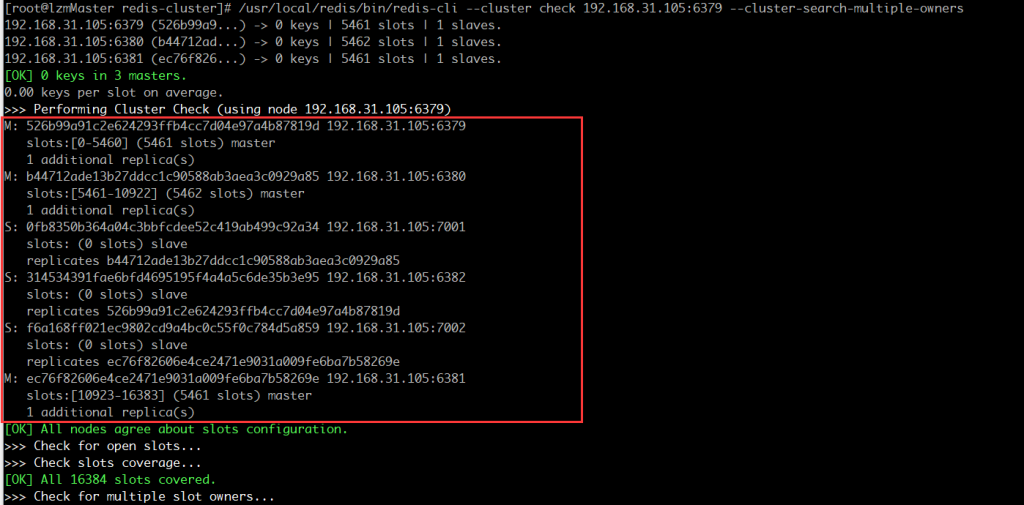
手滑配错的话,还可以 使用 del-node + ip + port + 实例id 来 删除某个节点,注意删除后此节点直接shutdown呦。

至此集群搭建完成。
来随便玩几个。。。
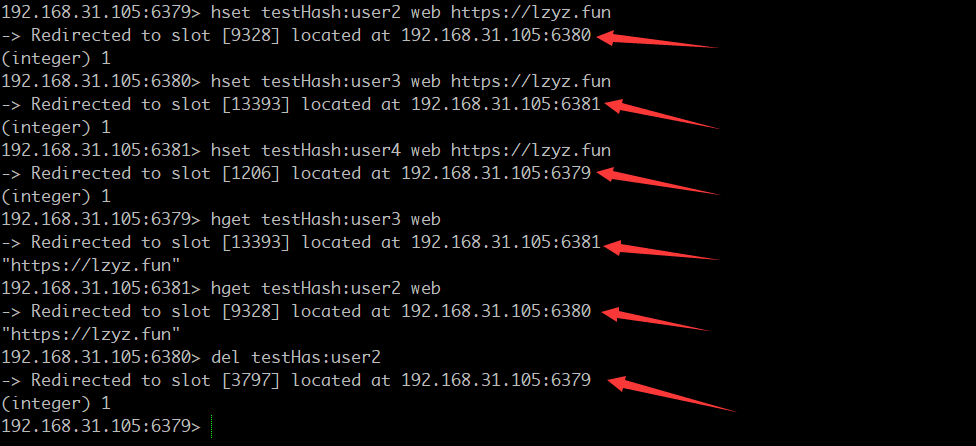
可以看到, Redirected to slot [xxxx] located at xxxx,证明了每个节点负责一部分hash slots 。
此步骤的坑:
大坑1:
使用check命令,发现会有红色报错:
[ERR] Not all 16384 slots are covered by nodes
大部分原因是由于主node移除了,但是并没有移除node上面的slot,从而导致了slot总数没有达到16384,其实也就是slots分布不正确。所以在删除节点的时候一定要注意删除的是否是Master主节点。
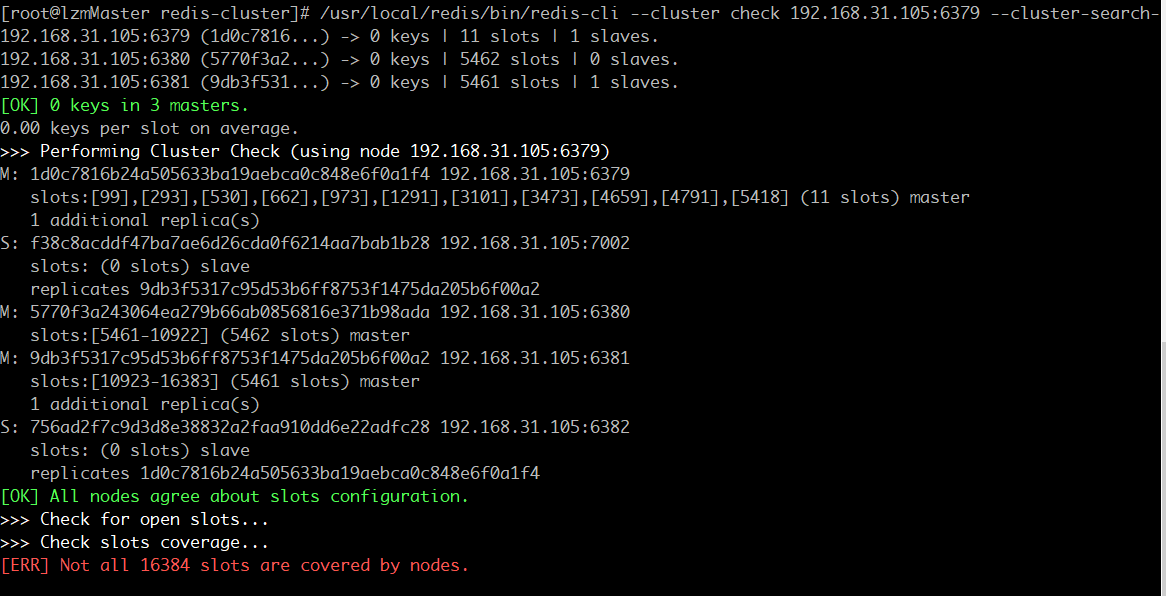
解决:
redis-cli --cluster fix 192.168.31.105:6397 --cluster-search-multiple-owners坑 2(这个是真坑 … ) :
报:Node 192.168.31.105:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.

1、删除此节点的redis启动时生成的.aof文件和.rdb文件;
2、将对应节点的“nodes-xxx。conf”文件(在上文配置的/home/ redis-cluster 文件夹中 nodes- xxx .conf)删除
3、(万不得已的选择)先flushDB然后shutdown,把新鲜出炉的空的dump.rdb放进bin目录下。
3、整合springBoot
项目依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>yml配置:
spring:
redis:
timeout: 5000 # 链接超时时间 单位 ms(毫秒)
cluster:
nodes:
- 192.168.31.105:6379
- 192.168.31.105:6380
- 192.168.31.105:6381
- 192.168.31.105:6382
- 192.168.31.105:7001
- 192.168.31.105:7002
max-redirects: 3
lettuce:
pool: # Redis 线程池设置
max-active: 8 # 连接池最大连接数(使用负值表示没有限制) 默认 8
max-wait: -1 # 连接池最大阻塞等待时间(使用负值表示没有限制) 默认 -1
max-idle: 8 # 连接池中的最大空闲连接 默认 8
min-idle: 0 # 连接池中的最小空闲连接 默认 0用一个以前的测试方法。
5分钟内连续登录错误5此,锁定5分钟,以此测试redis集群是否正常。
@Test
public void loginTest() {
String input_n = "lzm"; // 假设输入的用户名
String input_p = "1"; // 假设输入的密码
// 正确的账号为 lzm,密码http://lzyz.fun
System.out.println("登录时间:" + DateUtil.date() );
if( !(input_n.equals("lzm") && input_p.equals("http://lzyz.fun")) ){
if( redisUtils.hasKey("logErr", input_n) ){
Object errcount = redisUtils.hget("logErr", input_n, "errcount");
Object state = redisUtils.hget("logErr", input_n, "state");
int count = Integer.parseInt(String.valueOf(errcount));
if("lock".equals(String.valueOf(state))) {
long expire = redisUtils.getExpire("logErr", input_n);
System.out.println("此账号被锁定,请"+expire+"秒后再试。");
return;
}
int nums = ++count;
System.out.println(input_n + "错误次数:" +nums );
Map<String, Object> map = new HashMap<>();
if( nums < 5 ){
map.put("errcount", nums );
map.put("state", "intime" );
redisUtils.hmset("logErr", input_n, map );
}else{
map.put("errcount", 5 );
map.put("state", "lock" );
redisUtils.hmset("logErr", input_n, map , 300 );
System.out.println("账号已锁定。");
}
}
else{
Map<String, Object> map = new HashMap<>();
map.put("errcount", 1 );
map.put("state", "intime" );
// 第一次错误即设置5分钟。
redisUtils.hmset( "logErr", input_n , map, 300 );
System.out.println(input_n + "登录错误。" );
}
return;
}
System.out.println(" O(∩_∩)O 登陆成功!");
redisUtils.del("logErr", input_n );
}在连续错误5次后。。控制台输出

再看redis中:
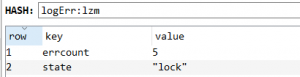
锁了。
RedisTemplate正常不代表运行lua就正常,因为在redis集群模式下lua脚本很容易会爆出两个错:
1、(error) CROSSSLOT Keys in request don’t hash to the same slot
和
2、Lua script attempted to access a non local key in a cluster node
先说错误1,是因为:
Redis要求单个Lua脚本操作的key必须在同一个节点上,但是Cluster会将数据自动分布到不同的节点(虚拟的16384个slot),阿里云集群版的官网其实也有对应说明:在Redis集群版实例中,事务、脚本等命令要求所有的key必须在同一个slot中,如果不在同一个slot中将返回以下错误信息(:command keys must in same slot)
如何解决?
CLUSTER KEYSLOT key的文档中提供了解决方法:你需将把key中的一部分使用{}包起来。
redis将通过{}中间你自定义的内容作为计算slot的key,类似key1{haha}、key2{haha}
取键中的一段字符来计算 hash,计算落入那个槽中,这样同一个功能不同的 key 就可以落入同一个槽位了,hash tag 就是通过{}这对括号括起来的字符串来找到家~
但是也有缺点,比如不能平滑的过度老业务,可能需要修改原来使用的key。
举个栗子,有这样一段代码:
redisTemplate.execute((RedisConnection connection) -> connection.eval(
redisScript.getScriptAsString().getBytes(),
ReturnType.INTEGER,
2,
key1.getBytes(),
key2.getBytes()
));我们会把key1和key2作为参数传入lua脚本,如果你直接传参,绝对报错。所以需要对key做一下处理:
String lua_key1 = key1+"{lua}";
String lua_key2 = key2+"{lua}";
redisTemplate.execute((RedisConnection connection) -> connection.eval(
redisScript.getScriptAsString().getBytes(),
ReturnType.INTEGER,
2,
lua_key1.getBytes(),
lua_key2.getBytes()
));干了什么?在key后边加了个字符串{lua},这样, 就可以落入同一个槽位了,hash tag 是通过{}这对括号括起来的字符串来判断的。
这里就可以引出错误2,会遇到我明明加了{}还是不行,此时就需要检查里面的字符串是否一致,而且,不能有数字,我到现在还在查阅相关文档这是为啥,还没查出来,希望路过的大神指点一下。
至此,关于docker搭建redis集群和相关的一些坑和总结就写完了。
感谢阅读~


非常感谢你分享这篇文章,我从中学到了很多新的知识。
鸟叔来串门,通过虫洞穿梭至此,期待回访!
感谢分享!